# 4. 리포지터리와 모델 구현
# 4.1 JPA를 이용한 리포지터리 구현
# 4.1.1 모듈 위치

- 리포지터리 인터페이스는 도메인 영역에, 구현체는 인프라스트럭처 영역에
- → 인프라스트럭처에 대한 의존 ↓
# 4.1.2 리포지터리 기본 기능 구현
- 인터페이스는 애그리거트 루트를 기준으로 작성
- 삭제 기능 : 관리자 페이지에서 삭제한 데이터 조회해야 하는 경우, 데이터 원복을 위해 일정 기간동안 데이터를 보관해야 하는 경우 등을 고려하여 삭제 기능 실행 시 바로 삭제하기 보다는 삭제 플래그를 사용해서 화면에 보여줄지 여부 결정
- 찾아보니 삭제한 데이터 보관용 테이블을 만드는 경우도 있었음 → 다 같은 테이블에 두는 것보다 조회 성능이 더 좋을듯
# 4.2 스프링 데이터 JPA를 이요한 리포지터리 구현
-
# 4.3 매핑 구현
# 4.3.1 엔티티와 밸류 기본 매핑 구현
- 애그리거트 루트는 엔티티이므로
@Entity로 매핑 설정 - 밸류는
@Embeddable, 밸류 타입 프로퍼티는@Embedded로 매핑 설정
@Entity // 루트 엔티티 Order
@Tagble(name = "purchase_order")
public class Order {
...
@Embedded
Orderer orderer;
}
@Embeddable //Order의 밸류
public class Orderer {
@Embedded
@AttributeOverrides( //MemberId에 정의되어있는 컬럼의 이름을 변경하기 위해 사용
@AttributeOverride(name = "id", column = @Column(name = "orderer_id"))
)
private MemberId memberId;
...
}
@Entity // Order의 밸류 타입 프로퍼티
@Table(name="purchase_order")
public class Order {
@Embedded
private Orderer orderer;
}
- Orderer 클래스가
밸류, Order 객체 내의 orderer 필드는밸류 타입 프로퍼티
# 4.3.2 기본 생성자
- JPA에서 @Entity와 @Embeddable로 클래스를 매핑하려면 기본 생성자를 제공해야 함
- 다른 클래스에서 온전하지 못한 객체를 만들지 못하게 하기 위해
protected로 선언
- 다른 클래스에서 온전하지 못한 객체를 만들지 못하게 하기 위해
# 4.3.3 필드 접근 방식 사용
- 프로퍼티 방식으로 JPA 매핑을 처리하면 쓸대없는 getter/setter를 추가해야 함
- 꼭 필드처리로 필요한 get 메서드 그리고 cancel(), changeShippingInfo() 등 도메인 기능을 구현하도록 하자
- @Access 어노테이션을 명시하지 않더라도 @Id나 @EmbeddedId 어노테이션이 필드에 있으면 필드 접근 방식이 자동으로 선택됨
- 어그리거트 루트에서만 설정되면 되고 밸류 객체들에는 따로 @Id나 @EmbeddedId 어노테이션 필요없음
# 4.3.4 AttributeConverter를 이용한 밸류 매핑 처리
public class Length {
private int value;
private String unit;
...
}
- 해당 객체를 100cm로 저장하고 싶으면? → AttributeConverter 사용
- 밸류 타입과 칼럼 데이터 간의 변환을 처리하기 위한 기능 정의
@Converter(autoApply = true)
public class LengthConverter implements AttributeConverter<Length, String> {
@Override
public String convertToDatabaseColumn(Length length) {
return length == null ? null : String.valueOf(length.getValue()) + " " + length.getUnit();
}
@Override
public Length convertToEntityAttribute(String dbData) {
if (dbData == null) return null;
String[] dbDatas = dbData.split(" ", 2);
return new Length(Integer.parseInt(dbDatas[0]), dbDatas[1]);
}
}
- @Converter의 autoApply 속성을 false로 지정하면 프로퍼티 값을 변환할 때 사용할 컨버터 직접 지정
public class Product {
@Column(name = "product_length")
@Convert(converter = LengthConverter.class)
private Length productLength;
}
# 4.3.5 밸류 컬렉션 : 별도 테이블 매핑
- 밸류 컬렉션을 따로 테이블로 매핑할 수도 있음
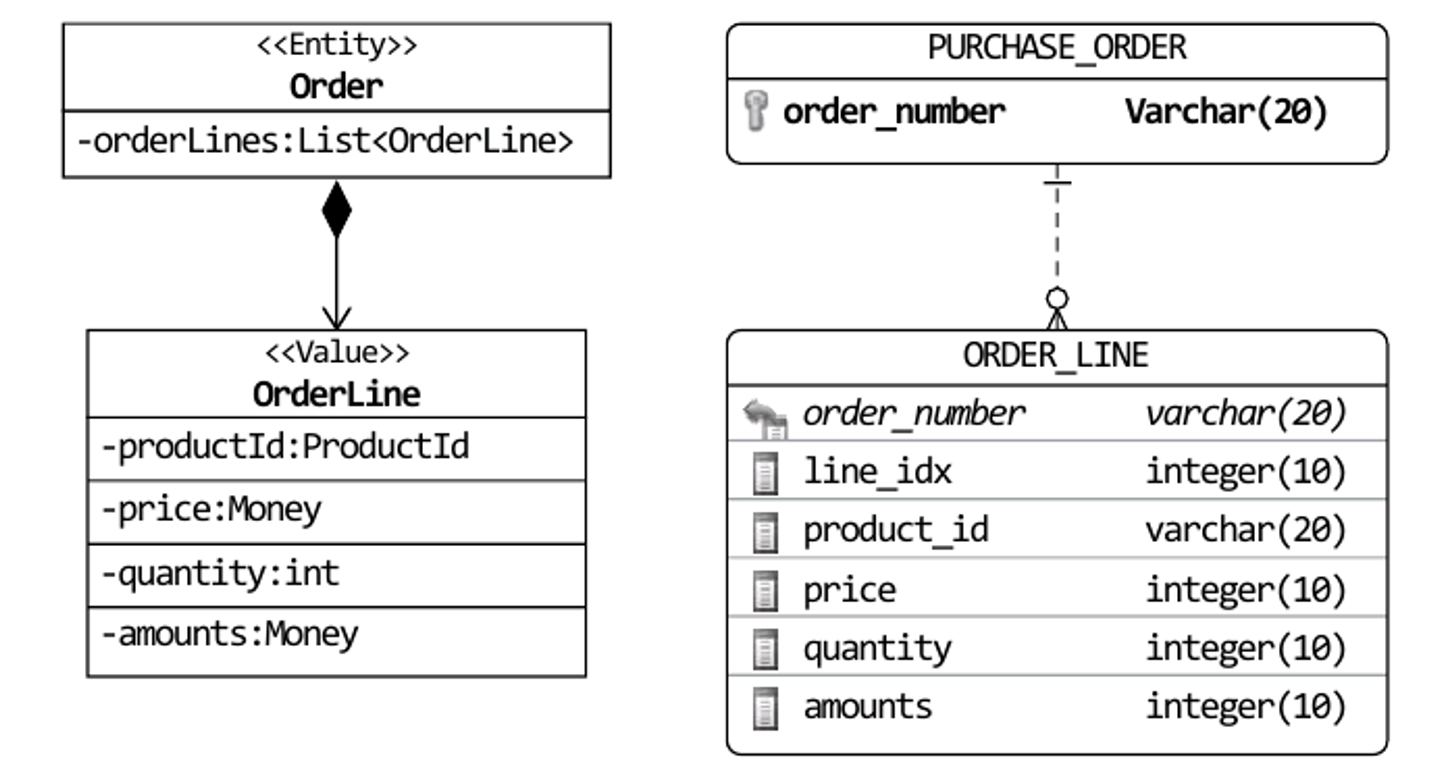
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderNo number;
...
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "order_line",
joinColumns = @JoinColumn(name = "order_number"))
@OrderColumn(name = "line_idx")
private List<OrderLine> orderLines;
...
}
@Embeddable
public class OrderLine {
@Embedded
private ProductId productId;
@Column(name = "price")
private Money price;
...
}
Q. 한번에 필요하면 모르겠는데 이렇게 하면 일단 N+1 문제 발생하지 않나?
# 4.3.6 밸류 컬렉션 : 한 개 칼럼 매핑
- AttributeConverter 사용
public class EmailSet {
private Set<Email> emails = new HashSet<>();
public EmailSet(Set<Email> emails) {
this.emails.addAll(emails);
}
public Set<Email> getEmails() {
return Collections.unmodifiableSet(emails);
}
}
public class EmailSetConverter implements AttributeConverter<EmailSet, String> {
@Override
public String convertToDatabaseDolumn(EmailSet attribute) {
if(attribute == null) return null;
return attribute.getEmails().stream()
map(email -> email.getAddress())
.collect(Collectors.joining(","));
}
@Override
public EmailSet convertToEntityAttribute(String dbData) {
if(dbData == null) return null;
String [] emails = dbData.split(",");
Set<Email> emailSet = Arrays.stream(emails)
.map(value -> new Email(value))
.collect(toSet());
return new EmailSet(emailSet);
}
}
@Convert(converter = EmailSetConverter.class)
private EmailSet emailSet;
# 4.3.7 밸류를 이용한 ID 매핑
- 식별자라는 의미 부각을 위해 식별자를 밸류 타입으로 만들 수 있음
@Entity
public class Order {
@EmbeddedId
private OrderNo orderNo;
}
@Embeddable
pblic class OrderNo implements Serializable {
@Column(name = "order_number")
private String number;
public boolean is2ndGeneration {
return number.startsWith("N");
}
}
- 이렇게 식별자에 기능 추가 가능
- 엔티티 비교로 equals(), hashcode() 값을 활용하므로 잘 구현해야 함
# 4.3.8 별도 테이블에 저장하는 밸류 매핑
- 애그리거트에서 루트 애그리거트를 빼면 대부분 밸류
- 별도 테이블에 저장됐더라도 진짜 엔티티인지 의심해 봐야 함
- ex) Order - OrderLine
- 밸류가 아니면 엔티티가 아니라 애그리거트는 아닌지 의심
- 자신만의 독자적인 생명 주기를 갖는다면 애그리거트일 수 있음
- ex) Product - Review
- 밸류와 엔티티 구별을 위해서 고유 식별자를 갖는지 확인
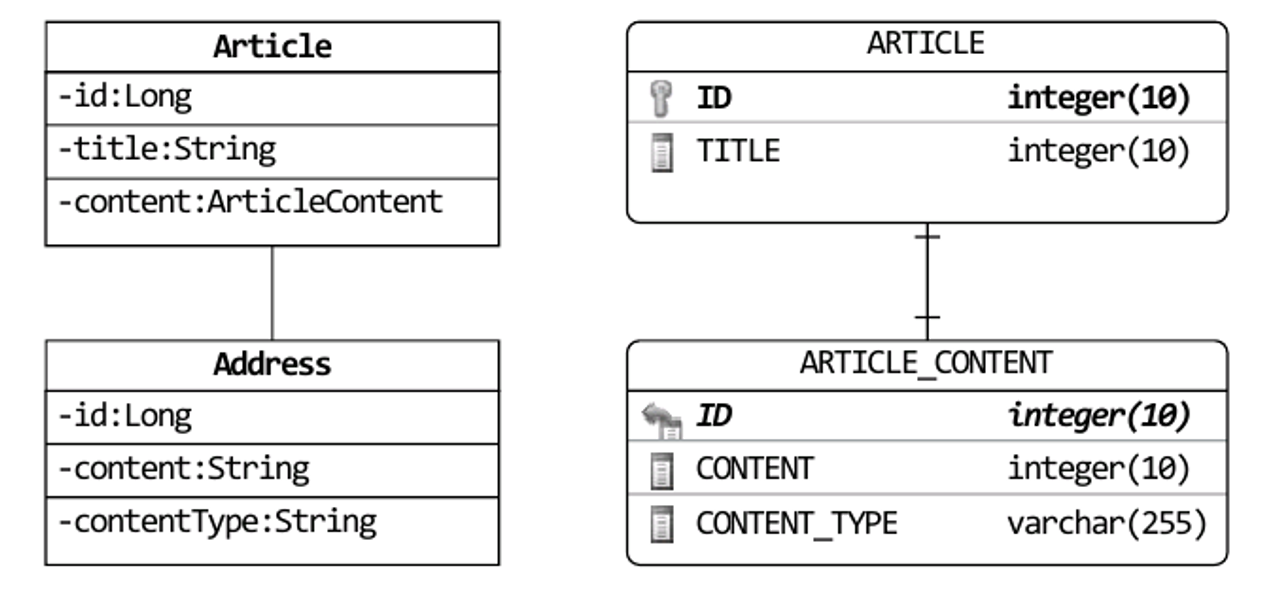
- 여기서 ArticleContent가 식별자가 존재한다고 1-1 연관으로 생각할 수 있지만 Article과 연결하기 위함이므로 밸류로 생각해야 함
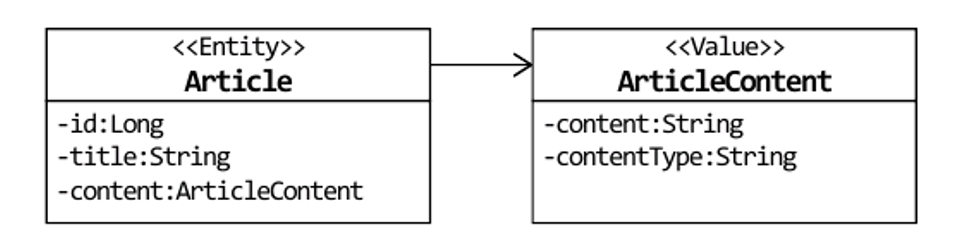
@Entity
@Table(name = "artice")
@SecondaryTable(name = "article_content", // 밸류 테이블 이름
pkJoinColumns = @PrimaryKeyJoinColumn(name = "id")) // 조인할 때 사용할 식별자
public class Article {
@Id
@GeneratedValue(IDENTITY)
private Long id;
private String title;
@AttributeOverrides({ // 칼럼명 지정
@AttributeOverride(
name = "content",
column = @Column(table = "article_content", name = "content")),
@AttributeOverride(
name = "contentType",
column = @Column(table = "artice_content", name = "content_type"))
})
@Embedded
private ArticleContent content;
}
엔티티에 임베디드/보조테이블 여러 개 사용하려면?
@Entity
@Table(name = "artice")
@SecondaryTable(name = "article_content", pkJoinColumns = @PrimaryKeyJoinColumn(name = "id"))
@SecondaryTable(name = "address", pkJoinColumns = @PrimaryKeyJoinColumn(name = "id"))
public class Article {
@Id
@GeneratedValue(IDENTITY)
private Long id;
private String title;
@AttributeOverrides({
@AttributeOverride(
name = "content",
column = @Column(table = "article_content", name = "content")),
@AttributeOverride(
name = "contentType",
column = @Column(table = "article_content", name = "content_type"))
})
@Embedded
private ArticleContent content;
@AttributeOverrides({
@AttributeOverride(
name = "foo",
column = @Column(table = "article_address", name = "foo"))
})
@Embedded
private Address address;
}
- 이 떄 필요없는 내용도 같이 조회할 수도 있는데(title만 필요한데 content도 같이 조회) 이건 조회 전용 쿼리로 해결
# 4.3.9 밸류 컬렉션을 @Entity로 매핑
- 밸류이지만 구현 기술의 한계나 팀 표준 때문에 @Entity를 사용해야 할 수도 있음
- 밸류 타입 자체에 상속 구조(ex: Image ← InternalImage, ExternalImage)를 사용할 수 없음
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE) // 한 테이블(Image)에 하위타입 모두 저장
@DiscriminatorColumn(name = "image_type") // 구분자 컬럼(하위 타입 구분)
@Table(name = "image")
public abstract class Image {
...
}
@Entity
@DiscriminatorValue("II") // InternalImage 구분자
public class InternalImage extends Image {
...
}
@Entity
@DiscriminatorValue("EI") // ExternalImage 구분자
public class ExternalImage extends Image {
...
}
- 근데 밸류는 불변이라 images를 바꾸려면
public void changeImages(List<Image> newImages) {
images.clear();
images.addAll(newImages);
}
- 이러면 product에서 image들 조회 쿼리 한 번 + delete 쿼리 image 개수만큼 n 번 → 성능상 별로
Q. 이거도 N+1 문제라 하나?
- 하이버네이트는 @Embeddable 타입에 대한 컬렉션의 clear() 메서드 호출 시 단 한 번의 delete 쿼리로 삭제 처리 수행
- 그래서 성능을 생각하면 다형성을 좀 포기하고 @Embeddable 쓰는게 나을 때도 있음
# 4.3.10 ID 참조와 조인 테이블을 이용한 단방향 M-N 매핑
@Entity
@Table(name = "product")
public class Product {
@EmbeddedId
private ProductId id;
@ElementCollection(fetch = FetchType.LAZY)
@CollectionTable(name = "product_category",
joinColumns = @JoinColumn(name = "product_id"))
private Set<CategoryId> categoryIds;
}
- Product 삭제 시 매핑에 사용한 데이터도 함께 삭제
# 4.4 애그리거트 로딩 전략
- 애그리거트 루트를 로딩하면 루트에 속한 모든 객체가 완전한 상태가 되어야 한다면?
- 조회 방식을 즉시 로딩으로 해야 함
@OneToMany(
cascade = {CascadeType.PERSIST, CascadeType.REMOVE},
orphanRemoval = true,
fetch = FetchType.EAGER
)
@JoinColumn(name = "product_id")
@OrderColumn(name = "list_idx")
private List<Image> images = new ArrayList<>();
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "product_option",
joinColumns = @JoinColumn(name = "product_id"))
private Set<OptionId> optionIds;
그치만 이게 항상 좋은 것은 아님
그럼 product, image, option을 조인하는데, 중복 데이터가 많아짐
JPA 1차 캐시에서 중복 검사 엄청 많이 하게 됨 → 성능 이슈 생김
즉, 애그리거트는 개념적으로만 하나면 됨 → 루트 애그리거트를 로딩하는 시점에 다 가져와야 할 필요는 없음
결국 애그리거트에 맞게 즉시 / 지연 로딩 선택해야 함
# 4.5 애그리거트의 영속성 전파
@OneToMany(
cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, // Product 의 저장/삭제 시 함께 저장 삭제
orphanRemoval = true, // images에서 Image 객체 제거 시 DB 에서도 함께 삭제
fetch = FetchType.LAZY
)
@JoinColumn(name = "product_id")
@OrderColumn(name = "list_idx")
private List<Image> images = new ArrayList<>();
- CascadeType.ALL, orphanRemoval = True 두 옵션 모두 사용 시 부모에서 자식 생명주기 관리 가능(생성, 삭제)
# 4.6 식별자 생성 기능
- 도메인 영역에 위치 시킬 수 있음(도메인 서비스)
- 리포지터리 인터페이스에 식별자 생성 메서드 추가해도 좋음
@RequiredArgsConstructor
public class WriteArticleService {
public Long write(newArticleRequest req) {
Article article = new Article("title", new ArticleContent("content", "type"));
articleRepository.save(article);
return article.getId(); // 저장 이후 식별자 사용 가능
}
}
- save의 persist는 생성된 키 바로 바인딩, merge는 새로운 객체 나오기 때문에 식별자 바인딩 안해줌
# 4.7 도메인 구현과 DIP
- @Entity, @Table, ... 쓰면서 JPA 구현 기술에 의존하고 있음
- 인프라에 도메인이 의존하고 있음
이런식으로 구현 기술을 변경하더라도 도메인이 받는 영향을 최소화 할 수 있음
근데 변경이 거의 없을긴데 이런더 대비하는건 좀 오바쌈바 → 타협 좀 하자
DIP는 지키되 개발 편의성과 실용성을 가져가면서 구조적인 유연함을 어느정도 유지하자